1. BIO AND INTERESTS
My name is Mark Strother, and I’m a 4th year physics graduate student here at UC Berkeley. So far, CS267 has already vastly improved my understanding of computation strategies I’ve encountered in my research. The course is titled “Applications of Parallel Computing,” and for me the emphasis is really on “applications.” My research involves physics at the nuclear-subnuclear length scale, or physics at length scales below L 
- Nuclei: The positively charged core of an atom, which is composed of
- Nucleons: The collective term for protons and neutrons, which themselves are composed of
- Quarks and gluons: Supposedly* fundamental particles appearing in the theory of quantum chromodynamics (QCD), the accepted theory of strong interactions.
The process of isolating different length scales and studying them individually is known as effective theory, and is related to the idea of the renormalization group, which dictates how a given physical theory changes when you zoom in or out. In an effective theory, it is possible to “bury” ignorance of physics occurring at ultra-short or ultra-long distances into a small set of parameters, giving you control over your theoretical description (re: predictive power). For a reference on these techniques applied in nuclear physics, see [1].
While nuclear physics can be divided this way, it is not always the case that physical processes can be organized in such a hierarchy. For instance, in molecular dynamics there are many different phenomena all occurring on the same length scale. In this case, such a separation of scales is impossible. That’s the good news. The problem is that, even if you can use effective theory for the problem, you still need a few basic input parameters. These parameters might be calculated within another theory, or they could be measured. In nuclear physics, however, it’s often the case that the calculation is impossible and the experimental data is not precise enough.
And this is jumping off point for “OHNOES COMPUTER PLZ HALP”.
While the applications of high-performance computing in nuclear physics abound, I’ve decided to spend the rest of the post discussing one in particular, called lattice QCD. The reason for doing this is because I’ve been fumbling around with lattice QCD software for about a year now and I still am not entirely sure how it works, and this assignment is a great opportunity to see what’s going on.
First of all, what is lattice QCD? Without going into a whole song and dance, lattice QCD is a method for numerically computing predictions of QCD that are otherwise incalculable. The difficulty stems from the fact that the strong force is…I mean it’s strong, right? When an interaction is weak, we can just pretend like we’re looking at a free theory (non-interacting), and then add the interactions as an after-thought. This perhaps sounds a bit implausible (unless you’re a physicist, in which case you’ll recognize it by the name of “perturbation theory”), but it happens to work very well. In fact, it’s about the only way of calculating things without resorting to numerics. Since QCD does not lend itself to perturbative calculations, we’re basically forced into putting on a discretized lattice and calculating everything numerically.
The idea of putting QCD on a lattice has been around since the mid 70s. Like so many fields of research, outsiders have been dissing its results, criticizing its slow progress, and questioning its overall usefulness since the beginning, whilst true believers have been championing it — “just a few more decades!” It has only been in the last 5-10 years that the field has reached maturity. Behold, the hadron spectrum, from a 2008 Science publication [2]:

There are a lot of other really interesting things I could talk about here, but I’ll save them for another post. Right now, I am going to talk about a small subset of computational tasks involved in a lattice QCD simulation and call it a night.
2. LATTICE QCD IN PARALLEL
The software I mentioned is called Chroma, and was developed by a collaboration called USQCD, as part of the Department of Energy’s SciDAC initiative (“Scientific Discovery through Advanced Computing”). As of writing this, Chroma consists of over 400,000+ lines of C++ code. It is a high-level interface that sits on top of various libraries that perform all the tasks needed for a lattice computation. The hierarchy is as follows [3]:

Some of these guys are not relevant from a HPC standpoint, but they appear [4] to cover the variety of programming models discussed in class:
- QDP++ : Stands for QCD Data Parallel (by the way, Q will always stand for QCD [like the G in GNU, but without the recursion]). QDP++ specifically deals with operations that are implemented at every space-time point on the lattice.
- QMP : QCD Message Passing, which to me is completely confusing — shouldn’t they have gone with QMPI, to avoid conflating this with multi-threading?
- QMT : Aha, here’s the multi-threading.
- QUDA : QCD implementation of CUDA — lattice calculations also take advantage of general purpose GPUs.
To name a few places where these processes are running, we have
- NERSC’s Edison and Hopper
- LLNL’s Oslic and Edge (Edge was retired recently in fact)
I mentioned above that LQCD has reached maturity. There are two main reasons this is happening now. First, it is a highly non-trivial matter to put a theory like QCD on a lattice. Lattice theorists have spent years trying to make sense of various technical issues. For example, the discretization and the finite volume can lead to what are known as “lattice artifacts” — new effects that aren’t present in the continuous, infinite volume theory. Furthermore, it is necessary to perform an extrapolation procedure when interpreting the results of a LQCD simulation, which is not a priori clear how to do. Plenty more examples abound — while some of the difficulties were to be expected, others were a complete surprise.
The second reason LQCD is finally hitting its stride is simply due to the co-development of computing resources. Computers have only recently progressed to the point where is feasible to do a calculation that is not totally overwhelmed by lattice artifacts. The majority of the computing resources go into inverting the “D-slash operator.” It’s a matrix of dimension on the order of 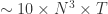
While people can come up with clever algorithms for inverting a matrix, there’s no changing the necessity of doing so, at least for a LQCD calculation. In an ideal world, the vision would be to first calculate properties of hadrons, then extend the programme to calculating hadron-hadron scattering. Indeed, this is an ongoing project, with some results already published by other collaborations [5]. But before we start trying to calculate Pb–>Au on a lattice, I will close this post on sort of a down note — there’s an Amdahl’s Law lurking here. The reason for the bottleneck actually comes from physics. As one begins adding more hadrons on the lattice, the work grows combinatorially, due to the diagrammatic procedure in quantum mechanics known as Wick’s Theorem. For the proton-proton scattering, there are on the order of thousands of diagrams for a given channel. That means thousands of D-slash matrices to invert.
Without getting too technical, what you measure on the lattice are objects called correlators. A correlator has a source and a sink. If you want to measure something like the proton mass, you need three sources and three sinks — three because of the three quarks to get the quantum numbers of the proton correct. What Wick’s Theorem tells you is that you need to sum over all the different ways to connect the various sources to sinks. This is fine for three quark operators, because that’s a total of 3 x 2 x 1 = 6 diagrams to sum over. But two protons? That’s six quark operators, or 6! = 720 diagrams, each with a D-slash matrix to invert. By the time you’re on helium-3, you’re looking at 9! = 362,880. Bottom line: if we are ever going to be able to continue lattice research into many body states, we’re going to need more than the speedup afforded by parallelization!
So, LQCD will have its moment in the sun. It is finally achieving its potential thanks to today’s modern supercomputers. Though it’s somewhat discouraging to know that its reach is finite, I am still very fortunate to be involved in a lattice collaboration while the field is in its prime.
[1] R. J. Furnstahl and K. Hebeler, Rep. Prog. Phys. 76 :126301 (2013)
[2] Durr, S., et al. (Budapest-Marseille-Wuppertal), Science 322, 1224 (2008)
[3] http://usqcd-software.github.io/
[4] R. G. Edward and B. Joo, Nucl.Phys.Proc.Suppl.140:832 (2005)
[5] NPLQCD Collaboration, Phys. Rev. D81:074506 (2010); CalLat Collaboration (publication in progress)
